
The Near Future of AI is Action-Driven
Exploring the astonishing near-term potential of Large Language Models.

In 2022, large language models (LLMs) finally got good. Specifically, Google and OpenAI led the way in creating foundation models that respond to instructions more usefully. For OpenAI, this came in the form of Instruct-GPT (OpenAI blogpost), while for Google this was reflected in their FLAN training method (Wei et al. 2022, arxiv), which beat the Hypermind forecast for MMLU performance two years early:
New paper + models!
We extend instruction finetuning by
1. scaling to 540B model
2. scaling to 1.8K finetuning tasks
3. finetuning on chain-of-thought (CoT) data
With these, our Flan-PaLM model achieves a new SoTA of 75.2% on MMLU. https://t.co/SBmrDnMFqz pic.twitter.com/5dsLFxHRUe— Hyung Won Chung (@hwchung27) October 21, 2022
But the best is yet to come. The really exciting applications will be action-driven, where the model acts like an agent choosing actions. And although academics can argue all day about the true definition of AGI, an action-driven LLM is going to look a lot like AGI.
Let’s act step by step
Famously, LLMs often perform better at question-answering tasks when prompted to “think step by step” (Kojima et al. 2022, arxiv). But they can do even better if they’re given external resources, or what I call external cognitive assets. The ReAct model puts these pieces together (Yao et al. 2022, arxiv). ReAct takes three steps iteratively: Thought (about what is needed), Act (choice of action), and Observation (see the outcome of the action). The actions often make use of cognitive assets like search. The authors give an example below:
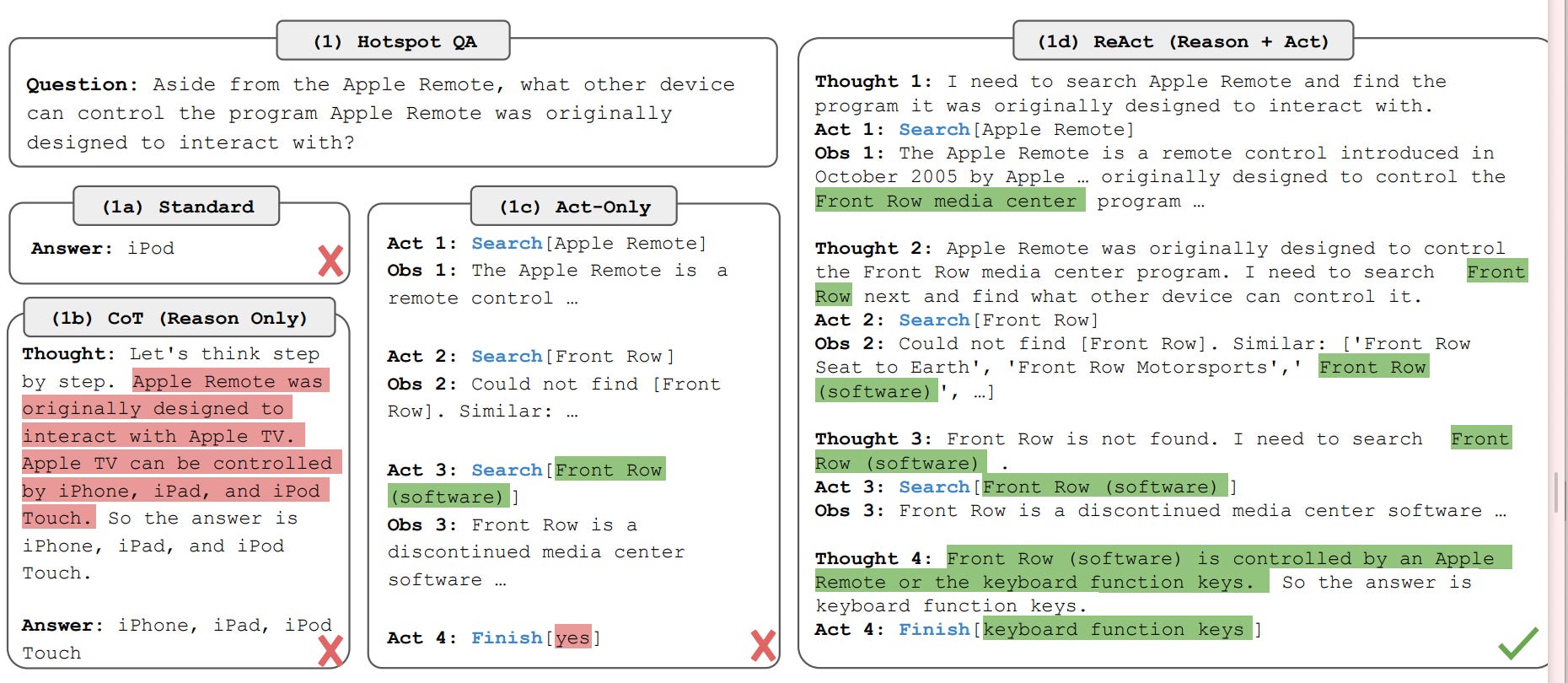
Here, the main actions the model uses above are Search and Finish. The authors also provided Lookup action that can search within the text of the article. In 1a/1b we can see the LLM doesn’t do very well answering the question on its own, because it doesn’t have enough information. In 1c we see that simply giving the algorithm a search function is not sufficient because the model seems to forget what it is doing by the time it hits the end. The authors’ approach of including both actions and specific thought steps is able to search deeply and find the answer.
Answering factual questions is useful, but for real-world tasks, providing LLMs with an array of tools can enable a much broader array of powers. Imagine a customer service LLM able to do React-style chaining. We might give it actions SearchDocs for information about the service and policies, SearchClientFacts to look up particular facts about a client, PythonCode to run python programs, ManualEscalation to submit cases to a human for approval, MessageClient to send the client messages, and Finish to indicate completion. I’ve fabricated a possible client assistance transcript below with React-style formatting:
Question: Client is asking if they can cancel their meal kit order.
Thought 1: I need to know our policy for cancelling orders.
Act 1: SearchDocs[Meal kit cancellation policy]
Obs 1: Meal kits can be cancelled up until 3 days before their ship date, after which manual escalation is necessary.
Thought 2: I need to know what the customer's ship date is.
Act 2: SearchClientFacts[NextShipDate]
Obs 2: '2022-12-03'
Thought 3: I need to know if that is 3 days from now.
Act 3: PythonCode[`from datetime import datetime; (datetime.strptime('2022-12-03', '%Y-%m-%d') - datetime.now()).days`]
Obs 3: 2
Thought 4: This means the cancellation will require a manual escalation.
Act 4: ManualEscalation[Client needs shipment cancelled.]
Obs 4: Case has been escalated to a human service provider.
Thought 5: I should tell the client what I have done.
Act 4: MessageClient["This order is happening in 2 days. That means we need to escalate to a manual cancellation. Please wait for a customer support person to reach out to you."]
Act 4: Message sent successfully
Thought 5: This means I am done.
Act 5: Finish[]We can now make agents that, on the basis of natural language questions or instructions, can perform actions in a wide action space. The potential is not limited to CX or sales any particular business workflow. Any set of behaviors where an agent manipulates symbols in a computer can in principle be performed with this schema. And it looks an awful lot like AGI.
This is not 10 year tech. It may be possible right now with off-the-shelf tools. But to make it work we need to set up the right feedback loops.
The importance of training
If you were to attempt the above CX example in the latest version of GPT-3, it’s unlikely that you would get consistently good behavior. The LLM needs to understand the power of its own tools and it needs to know what kinds of outcomes we the user desire.
There are many tools for doing this. Google Brain recently achieved SOTA question-answering performance via instruction tuning (arxiv). The secret to OpenAI’s 002-text-davinci model seems to be attributable to a combination of instruction tuning and Reinforcement learning from Human Feedback (RLHF, blogpost), wherein humans rate the success of a given prompt. The ReAct paper takes advantage of a method developed by Zelikman et al. (2022, arxiv) to bootstrap a large number of “valid” chains for training by using LLMs to generate them. I suspect that the very best results will come from actual reinforcement learning where a system can actually be trained to produce better results as measured via a metric of interest. For example, consider a model generating marketing copy that could be trained on conversion rate data to produce copy with consistently higher conversion.
Implementing a powerful AI feedback loop.
Schematically, the stack for a successful action-driven deployment will look something like this:
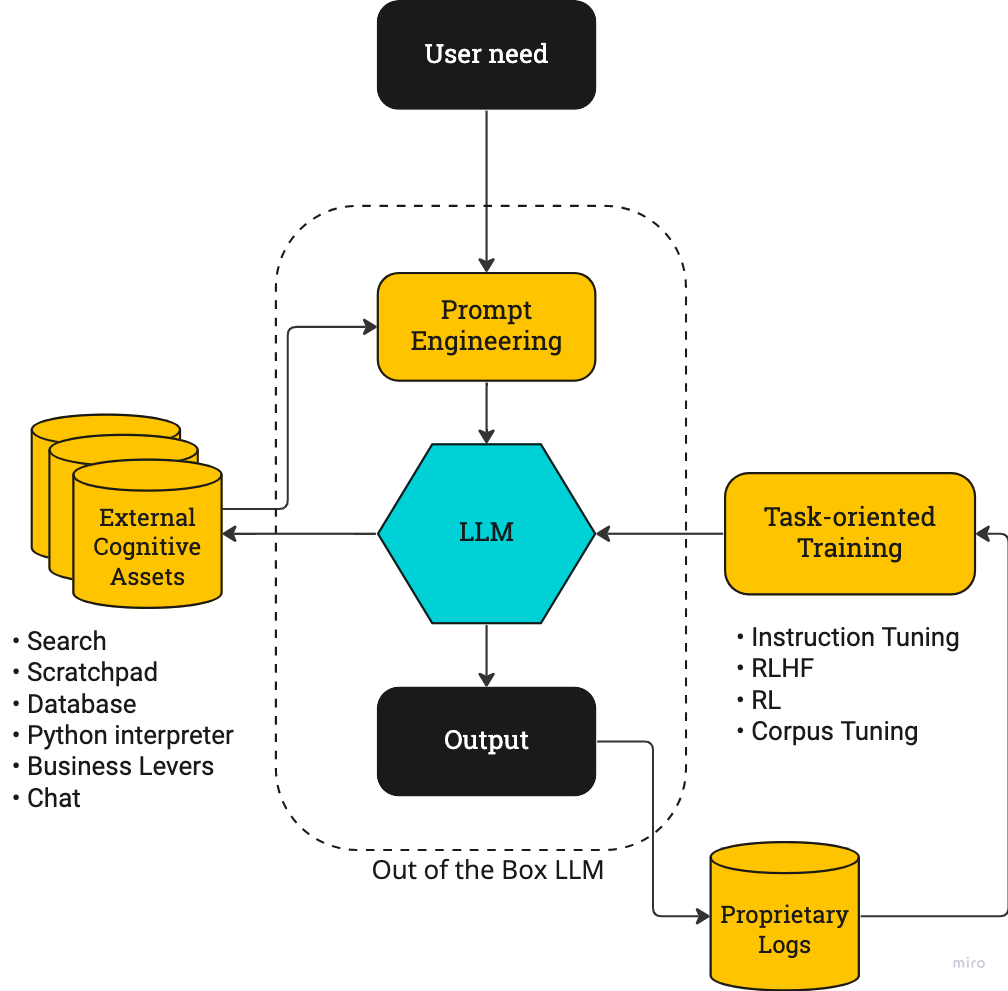
In the middle we have the “out of the box” foundation model. Prompts are engineered to ask for outcomes, passed into the LLM, and an output is received. Many of the recent “LLM” startups take advantage roughly of this toolset. Instruct GPT has made OpenAI’s version of this stack particularly easy to get started with.
On the left we have the External Cognitive Assets that can supercharge a model’s power. These can be any function that takes text as an input and provides text as an output, including searches, code interpreters, and chats with humans.
Finally on the right we have the task oriented training that’s needed to make this work well. This is the hard part. Some techniques, like instruction tuning, seem fairly straightforward to implement. RLHF is harder and involves tuning a PPO algorithm (OpenAI post). RL will particularly benefit from proprietary datasets, especially usage logs.
Some startups will become very successful creating powerful feedback loops: Solving a customer pain point (maybe bootstrapping by starting with something very simple), collecting data about how to solve that better, training their models to be more consistent, and iterating. This is roughly what a moat will look like in AI, at least for now. But as the agents get more domain-general, the spaces that can be automated and offerings that are possible will expand.
Early steps
We’ve already seen a few demos of giving models superpowers like this. For example Sergey Karayev showed what can already happen when you give an LLM a Python interpreter:
Here's a brief glimpse of our INCREDIBLE near future.
GPT-3 armed with a Python interpreter can
· do exact math
· make API requests
· answer in unprecedented ways
Thanks to @goodside and @amasad for the idea and repl!
Play with it: https://t.co/uY2nqtdRjp pic.twitter.com/JnkiUyTQx1— Sergey Karayev (@sergeykarayev) September 12, 2022
And the team at Adept built a model that can surf the web and perform basic tasks:
1/7 We built a new model! It’s called Action Transformer (ACT-1) and we taught it to use a bunch of software tools. In this first video, the user simply types a high-level request and ACT-1 does the rest. Read on to see more examples ⬇️ pic.twitter.com/mq7c0Vyd7N
— Adept (@AdeptAILabs) September 14, 2022
In terms of implementation, LangChain makes it easy to chain prompts together and provide LLMs with tools:
🚨Biggest @LangChainAI drop yet🚨
⚡️Dynamic, zero-shot composition of multiple chains
Easily plug in different subchains (google, REPL, wikipedia, DBs) just by telling the router LLM (in English!) when and how to use them
`pip install langchain==0.0.8`https://t.co/vxBzH0v5F9 pic.twitter.com/nItA7T0gKl— Harrison Chase (@hwchase17) November 7, 2022
Dust.tt provides a web app and alternative model for chaining prompt components:
@dust4ai takes some work to wrap your head around, but it's very powerful — gives a collapsible tree UI for representing k-shot example datasets, prompt templates, and prompt chaining with intermediate JS code. Replaces a lot of code around prompt APIs. https://t.co/l4Gi2MEFsO pic.twitter.com/ScwqIRyU4j
— Riley Goodside (@goodside) November 3, 2022
These systems are not a theoretical academic demo. You can hack on them starting now. Over the next few months we’re going to see increasingly surprising and useful applications rolling out. If you can think of a job that involves manipulating symbols on a computer: Action-driven AI is coming. I’m looking forward to covering this as it unfolds, but a few things I’m specifically planning to cover:
How do you actually build the stack in the diagram above, incorporating both external cognitive assets and training?
What’s the deal with instruction tuning? Is it actually so great? How does Instruction Tuning and RLHF actually work? Why is this hard? Can we make it easy?
What will the market look like? What sort of products does this space need to succeed? What sort of startups will thrive?
What does the rise of agentic algorithms mean for media and society? My hope is that there will be a rebalance of power of algorithms in favor of the consumer, but much remains in the air. I learned a lot building vibecheck.network.
Stay tuned! …and reach out if you want to chat or collaborate.
PS: A note on alignment
I’m not an expert on alignment but if this sort of stack really does work, it is the AGI Fire alarm. If we can build a system that can take real world actions to achieve useful goals, all the pieces are in place for a very powerful AI to be created. If you are in this space and building machines like this it is incumbent on you to learn about AI alignment risks and consider how you plan to maintain alignment with your system early on. If you are a bit skeptical or want to learn more, you might be interested in Stuart Russell’s book Human Compatible [amazon]. Russell is a lifelong AI researcher and speaks as a domain expert, not a wild-eyed doomer. For the lazy, Scott Alexander reviews it here.
John McDonnell is a current SPC member and former Director of Machine Learning at StitchFix. This article was originally published on John's Substack Causal Deference.